11 Knowledge Graph Embedding
A knowledge graph is a graph of data intended to convey knowledge of the real world. Nodes represent entities, while edges represent binary relations between entities. Data graphs are potentially enhanced with schema to provide meaning.
KGs are grounded in the Open World Assumption. The most used representation languages are RDF, RDFS, and OWL. They can represent very large data collections, but they can suffer from incompleteness and noise.
11.1 ML on KG
Tasks possible with KGs are:
- Link prediction: predicts missing links between entities, can be regarded as a learning to rank problem
- Triple classification: assesses correctness of a statement with respect to a knowledge graph, can be regarded as a binary classification problem
- Link-based clustering (for example to do customer segmentation)
- Entity matching for duplicate detection or deduplication
We have two different possible perspectives:
- KG as input to ML: the goal is to improve the performance in many learning tasks
- ML as input to KG: the goal is to improve the KG itself, by creating new facts, generalizations, improving the size, coverage, depth, accuracy and, in general to remove noise and incompleteness
11.1.1 Link prediction
We can employ traditional relational learning:
- Logic programming: predict new links from facts and rules
- Inductive Logic Programming: predict new links from rules extracted from facts
- Rule mining: extracts Horn clauses based on their support in the KG
- Graphical Models
The limitations are the limited scalability to KG size and the limited expressiveness.
Given the very large data collections new scalable Machine Learning methods are needed, grounded on numeric-based approaches, like vector embedding.
11.2 Embeddings
KGE models convert data graph into an optimal low-dimensional space, preserving as much as possible graph structural information and properties.
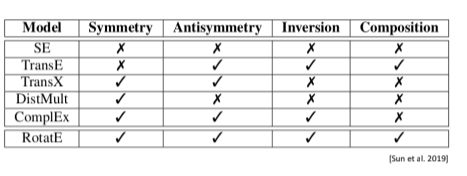
The properties to be retained are:
- Symmetry: < Alice marriedTo Bob>
- Asymmetry: < Alice childOf Jack>
- Inversion: < Alice childOf Jack>, < Jack fatherOf Alice>
- Composition: < Alice childOf Jack>, < Jack siblingOf Mary>, < Alice nieceOf Mary>
- Hierarchies
11.3 General KB Embedding Pipeline
The goal is to learn embeddings such that the score of a valid positive triple is higher than the score of an invalid negative triple.
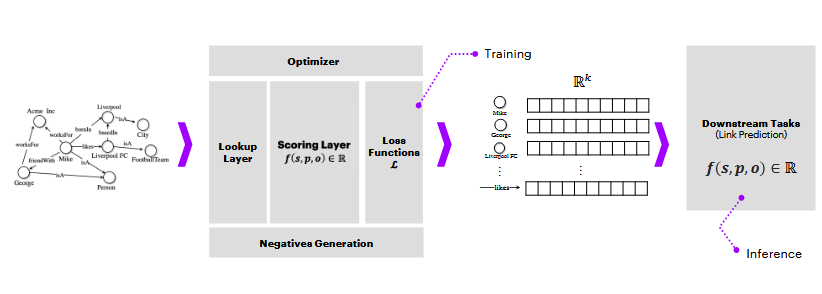
11.3.1 Anatomy of a KGE Model
- Knowledge Graph \mathcal{G}
- Lookup layer
- Scoring function for a triple f(t)
- High score = high chances for the triple to be a true fact
- Loss function \mathcal{L}
- Optimization algorithm
- Negatives generation strategy
11.3.2 Scoring functions
TransE: Translating Embeddings f_{TransE} = - ||(e_s + r_p) - e_o||_n
e_s is the vector for the subject
r_p is the vector for the relation
e_o is the vector for the object
The idea is that for a true fact taking the subject vector and adding the vector for the relation, you should end up at a point in the vector space that is very close to the object vector.
- RotatE: relations are modeled as rotations in complex space \mathcal{C} using element-wise product between embeddings
f_{RotatE} = - ||e_s r_p - e_o||_n
- Models based on tensor factorization:
- RESCAL: f_{RESCAL} = e_s^TW_r e_o; it does not scale well
- DistMul: f_{DistMult} = <r_p, e_s, e_o> (dot product)
- ComplEx: DistMult with dot product in \mathcal{C}
- Models based on neural network
- ConvE: reshaping + convolution
- ConvKB: convolutions and dot product
- They are computationally expensive!
11.3.3 Loss functions
Pairwise Margin-Based Hinge Loss (used by TransE) \mathcal{L}(x) = \sum_{t^+ \in G} \sum_{t^- \in C} \max(0, [\gamma + f(t^-; x) - f(t^+; x)])
\max(0, [\gamma + f(t^-; x) - f(t^+; x)]): pays a penalty if score of positive triple is less than the score of synthetic negative by a margin \gamma
f(t^-; x): score assigned to a synthetic negative
f(t^+; x): score assigned to true triple
Cross-Entropy
Binary Cross-Entropy
11.3.4 Negatives Generation
If we assume the Local Closed World Assumption, that is, the KG is only locally complete, we can generate negative by corrupting triples present in the KG. The corruption is employed by changing the subject or the object of a triple, while the predicate is unaltered.
How many negatives for a positive?
- Uniform sampling: generate all possible synthetic negatives and sample n negative for each positive t
- Complete set: use all possible synthetic negatives. We need to mind the scalability and the fact that we can come up with false negatives (triples actually present in the KG)
- 1-n scoring: we take batches of (s, r) pair and score it against all entities o \in Train simultaneously, labeling as positives if that pair is in training KG or negatives if that pair is not in training KG
11.3.5 Evaluation Metrics for Link prediction
Mean Rank: (sensitive to outlier) MR = \dfrac{1}{|Q|} \sum_{i = 1}^{|Q|} rank_{(s, p, o)_i}
Mean Reciprocal Rank: (less sensitive to outlier) MRR = \dfrac{1}{|Q|} \sum_{i = 1}^{|Q|} \dfrac{1}{rank_{(s, p, o)_i}}
Hits@N: count positive examples in the first N positions Hits@N = \sum_{i = 1}^{|Q|} 1 \; \text{if} \; \text{rank}_{(s, p, o)_i} \le N